
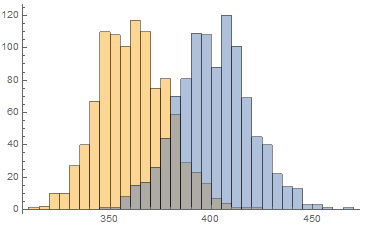
スロットマシンが2台あり、片方は18%の確率で当たり、もう片方は20%の確率で当たる。上グラフは共に2000回スロットを回して当たりが出た回数を数える、それを1000回試行して描いたヒストグラムである。山が左にあるほう(オレンジ色)が確率18%の台で、山が右にあるほう(水色)が確率20%の台である。どちらが確率20%なのか判別したい。
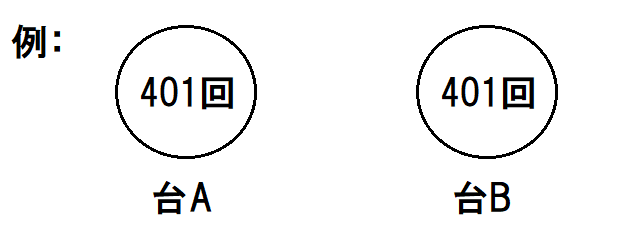
本当は台Bが2%だけ多く当たる(確率18% vs. 確率20%)
しかし、たとえば2000回も回して、両方が同じ回数だけ当たった場合に、どちらがどちらなのか全く区別がつかない。
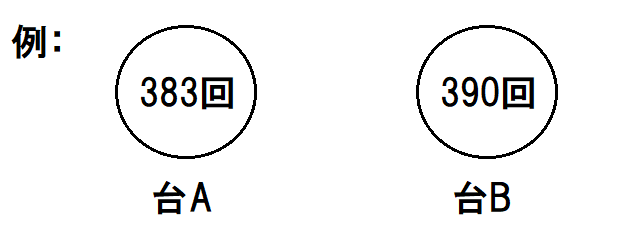
本当は台Bが2%だけ多く当たる(確率18% vs. 確率20%)
また、より多く当たった台が、たとえば(当たり回数が)390回だった場合、偶然に確率18%の台が勝ってしまった可能性は否定できない。不安になる。(※上図だと無事に確率20%の台が勝ってはいるものの。)
少し賢明なやり方を紹介すると、直近2000回で21%の頻度で(つまり420回)当たりがでるまで両方のスロットを回し続けて、先に直近の2000回(3980回も回したら1981回目以降で)そのようになったほうを確率20%の台と断定すると、ほぼ100%で判別できる。ただし、スロットを無限に回してよいのであれば、単純に10000回でも1000000回でも回して、適当に多い方を選んでしまえばよいと思う(※たとえば確率19.8%と確率20%の台の判別は、ただ1試行をひたすら回して納得がいく差がつくのを待つやり方が一旦手短である。)つまり何回までスロットを回して構わないのかを関心事にしないと、こうした話題は「研究(サイエンス)」といった世界に持ち込めない。どのような統計的手法が適切かのサイエンスは情報処理の分野に越境していくのである。


